简介
任务:利用Keras建立LSTM模型,基于股票历史价格实现对未来对预测。
模型整体结构:双层LSTM+全连接层
说明:以下只是部分代码,如需完整代码,可留邮箱,欢迎交流。
获取数据
利用tushare接口获取股票历史信息;将数据索引改为datatime格式,并按其排序。
def get_home_data(num, start, end):
tushare接口获取dataframe数据,数据索引为datetime格式,并按照datetime升序排列。
:param num:str,stock code
:param start:str,like 2019-08-01
:param end:str,like 2019-08-01
:return:dataframe,index is datetime and ascending by datetime
try:
data_df = ts.get_hist_data(num, start=start, end=end)
data_df.index = data_df.index.astype(datetime64[ns])
data_df = data_df.sort_index()
print(股票数据获取完成!)
return data_df
except Exception:
print(股票获取失败!)
data = get_home_data(600570, 2018-09-01, 2019-11-05)
特征选取
选择收盘价为历史特征,并转为array数据结构。后续可选择其他的特征做尝试。
array = data[close].values
if array.ndim == 1:
array = array.reshape(-1, 1)
数据预处理
将数据标准化。后续可对数据噪声处理做尝试。
def preprocess(array):
:param data: numpy
:return:
from sklearn.preprocessing import MinMaxScaler
scl = MinMaxScaler()
array = scl.fit_transform(array)
return array, scl
normalize_data, scl = preprocess(array)
切分训练数据和测试数据
将预处理后的数据切分,具体代码如下。forward_days代表所要预测forward_days天的股票价格,将最新的num_periods*forward_days天的数据作为模型的测试数据。代码第二行,测试数据需包括前look_back天,以便对测试数据做预测。
division = len(normalize_data) - config.num_periods * config.forward_days
array_test = normalize_data[division - config.look_back:]
array_train = normalize_data[:division]
因训练数据和测试数据构造训练集和测试集的步长不一致,因此需在构造样本前先切分。步长不一致的原因是为了模型在测试数据效果的可视化。
构造LSTM样本
具体代码如下所示。LSTM模型的时间步长为look_back变量,对未来forward_days天的价格做预测。以时间步长为1建立训练集,以时间步长forward_days建立测试集合。对测试集合进行forward_days处理的目的是为了后续可视化。
def sample_to_data(data, look_back=40, forward_days=10, jump=1):
X, Y = [], []
for i in range(0, len(data) - look_back - forward_days + 1, jump):
X.append(data[i:(i + look_back)])
Y.append(data[(i + look_back):(i + look_back + forward_days)])
return np.array(X), np.array(Y)
X, y = sample_to_data(array_train, config.look_back, config.forward_days)
X_test, y_test = sample_to_data(array_test, config.look_back, config.forward_days, config.forward_days)
训练集切分为训练集和验证集
验证集用于调参
from sklearn.model_selection import train_test_split
X_train, X_validate, y_train, y_validate = train_test_split(X, y, test_size=0.20, random_state=42)
训练模型
定义模型结构
model = Sequential()
model.add(LSTM(NUM_NEURONS_FirstLayer, input_shape=(config.look_back, 1), return_sequences=True))
model.add(LSTM(NUM_NEURONS_SecondLayer))
model.add(Dense(config.forward_days))
model.compile(loss=mean_squared_error, optimizer=adam)
将数据送入模型训练
history = model.fit(X_train, y_train, epochs=EPOCHS, validation_data=(X_validate, y_validate), shuffle=True, batch_size=2, verbose=2)
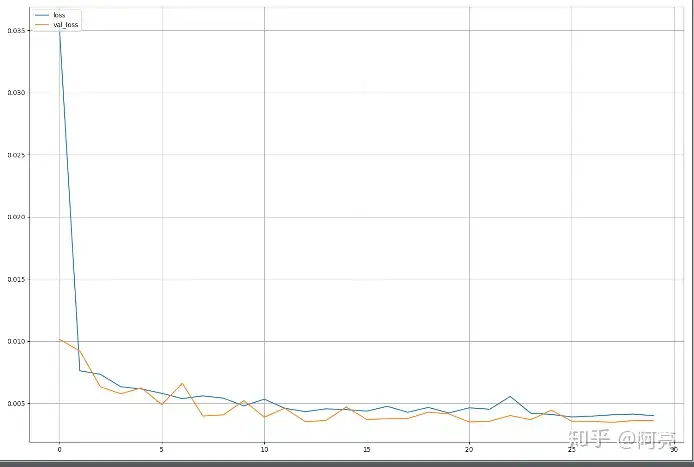
训练过程画图,可根据此图判断模型拟合程度,进而调参。
plot_figure(history.history,[loss,val_loss])
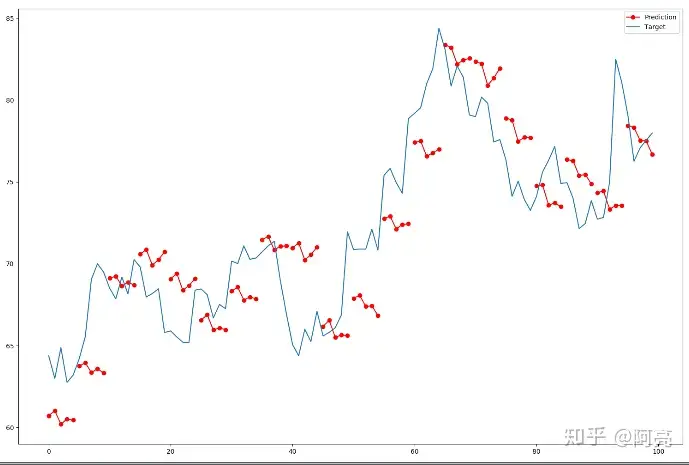
模型在测试集效果
测试集送入模型
Xt = model.predict(X_test)
画出测试集的预测效果和真实值做对比。首先将模型预测的价格反向标准化,分段画出并标记为红色;其次,将真实值反向标准化画出。
plt.figure(figsize=(15, 10))
for i in range(0, len(Xt)):
plt.plot([x + i * config.forward_days for x in range(len(Xt[i]))], scl.inverse_transform(Xt[i].reshape(-1, 1)), color=r)
plt.plot(0, scl.inverse_transform(Xt[0].reshape(-1, 1))[0], color=r, label=Prediction) # 巧妙对分段函数进行标注
plt.plot(scl.inverse_transform(y_test.reshape(-1, 1)), label=Target)
plt.legend(loc=best)
plt.show()
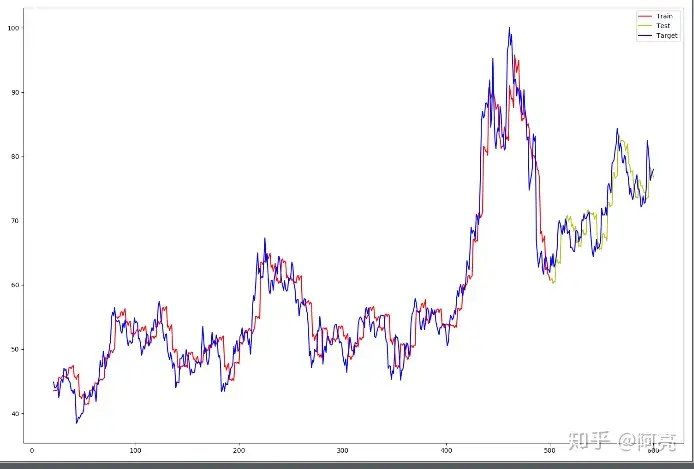
模型在训练集和测试集的效果
准备对训练集进行预测,为了保证计算计算训练集从哪个位置开始
division = len(normalize_data) - config.num_periods*config.forward_days
leftover = division%config.forward_days
while(leftover<config.look_back):
leftover+=config.look_back
array_train = normalize_data[leftover-config.look_back:division]
array_test = normalize_data[division-config.look_back:]
Xtrain,ytrain = sample_to_data(array_train,config.look_back,config.forward_days,config.forward_days)
Xtest,ytest = sample_to_data(array_test,config.look_back,config.forward_days,config.forward_days)
Xtrain = model.predict(Xtrain)
Xtrain = Xtrain.ravel()
Xtest = model.predict(Xtest)
Xtest = Xtest.ravel()
y = np.concatenate((ytrain, ytest), axis=0)
plt.figure(figsize = (15,10))
# Data in Train/Validation
plt.plot([x for x in range(leftover, len(Xtrain)+leftover)], scl.inverse_transform(Xtrain.reshape(-1,1)), color=r, label=Train)
# Data in Test
plt.plot([x for x in range(leftover+ len(Xtrain), len(Xtrain)+len(Xtest)+leftover)], scl.inverse_transform(Xtest.reshape(-1,1)), color=y, label=Test)
#Data used
plt.plot([x for x in range(leftover, leftover+len(Xtrain)+len(Xtest))], scl.inverse_transform(y.reshape(-1,1)), color=b, label=Target)
plt.legend(loc=best)
plt.show()
需改进之处:
特征只选了股票收盘价,可在ma值等方面做尝试。数据预处理太单薄,可增加平滑处理等做尝试。各时间段样本权重不应相同,可对近时间样本加权做尝试。样本数量还是过少,结合多只股票数据训练会不会更好。模型直接输出了股票未来段时间的价格,忽略了段时间价格彼此是联系的,后续需对模型结果做改进,在预测一天股价对基础上,再对下一天做预测。这也是所预测段时间价格趋势相同的原因,是极为不合理的。直接预测股价有局限性,转为分类任务会不会更好,类别为大涨、小涨、小跌、大跌。学习回测系统,实际查看模型表现。强化学习和LSTM的结合。







评论
8001直播
回复精华帖的节奏啊!http://33q.sy00066.com
下载时光娱乐极速版
回复论坛人气好旺!http://87vq60.dbbdoor.com
实时台湾宾果彩票网
回复有钱、有房、有车,人人都想!http://ret.zjqf05.com
游客
回复这么版块的帖子越来越有深度了!http://www.a5km.com/yxgl/dnf/23489.html